Web-based search tool filtering recipes online based on 14 allergen groups.
For the project to be successful, the following methodology and key steps will be undertaken:
- Define the scope:
The Scope of this project is to design, develop, test and evaluate a prototype web-based search tool that allows for the identification and filtering of online recipes based on fourteen allergen groups defined by the UK and EU legislation.
The tool will:
- utilise web scraping to find , collect and extract key recipe data from selected websites and open source datasets.
- use text processing methods to identify allergens,
- store the processed data in a structured database,
- allow users to filter out unwanted allergens from recipes through interactive faceted search filters.
2. Define clear objectives:
- Research on existing recipe search platforms and faceted search, allergen awareness and existing allergen labelling practices, web scraping methods, web-based systems and user interface for users with dietary restrictions, and ethical and legal aspects of web scraping and designing interfaces within health-related environments.
- Develop a web scraping system to find and extract recipe data from ethical sources available online.
- Implement data preprocessing, cleaning and tokenisation for recipe standardisation.
- Design and implement an allergen detection system based on keyword text analysis and matching.
- Build a structured database to store scraped and processed recipe data.
- Develop web web-based user-friendly interface that allows for faceted search filtering.
- Test and evaluate the search tool for usability, functionality, accuracy, accessibility and user trust.
- Discuss ethical and legal aspects in relation to ethical web scraping, data collection, use and storage, and ensuring compliance with ‘robot.txt’ files and websites’ terms and conditions as well as data protection legislation.
3. Design the evaluation approach to assess the progress, effectiveness and the quality of the final product:
- Considering usability and performance assessment, a mixed-methods usability evaluation approach will align with the aim of the project and give strong evidence,
- This approach will combine quantitative evaluation of usability based on performance, including:
– Error rate,
– task success rate,
– task completion time,
– SUS score.
These metrics are statistically significant and will give strong objective evidence of the effectiveness of the tool,
- With a Qualitative usability evaluation based on data collected from user feedback by employing:
– interviews,
– open-ended questionnaire,
– observations while using the tool.
This data provides another layer of depth to the qualitative findings and will help with understanding ‘why’ the tool is working or will reveal any issues with usability.
- Comparative evaluation – the evaluation metrics of the web scraping enhanced tool will be compared with a baseline condition, such as a standard recipe search. The metrics used in this approach include:
– accuracy,
– speed,
– satisfaction and confidence,
– allergen detection success rate.
4. Collect the data – gather all relevant data using above methods.
5. Analyse the results by processing the collected data by utilising statistical analysis, comparative metrics and user evaluation insights.
6. Report the findings and reflect on success rate and any issues, and future improvements.
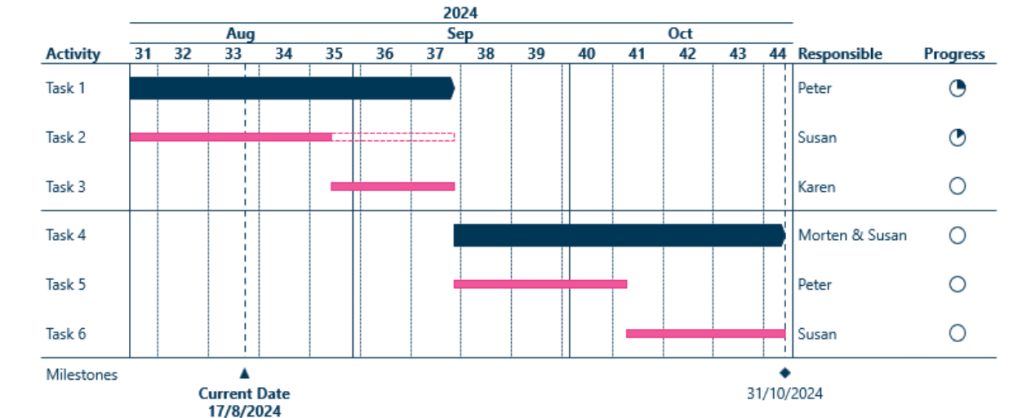
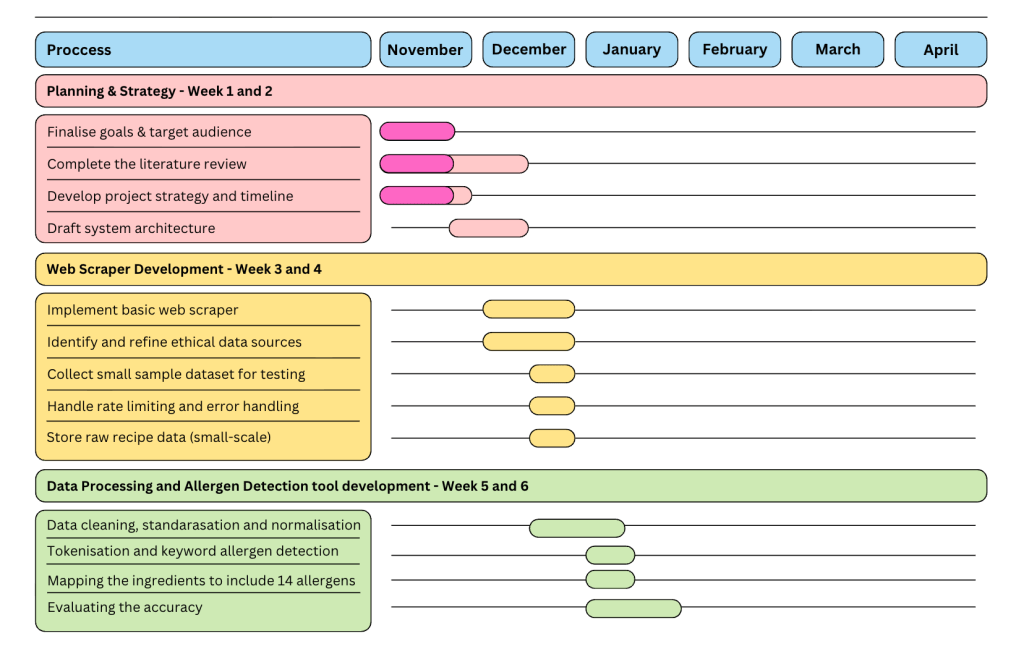
The following Gantt Chart shows an initial timeline to help with the project management and to monitor the progress:



References:
Strba, M. (2025) Evaluation Research Methods [online] Available from: https://www.uxtweak.com/evaluation-research/methods/ [Accessed: 22 November 2025]